layer2介绍
layer2方案和独立链的主要不同点在于DA,layer2中,DA由以太坊控制,layer2仅负责运算,意味着用户数据的安全性完全由以太坊保障,layer2只是个工具人,无法作恶,最多恶心一下你,比如不打包你的交易(Censorship)。
但DA由以太坊控制也有缺点,最大的问题就是扩容能力远远比不上独立链,tps比不上独立链,gas也没有独立链低。毕竟layer2需要把交易打包到以太坊,这个过程即消耗时间,也消耗gas。
除此之外,layer2的机制和独立链有很多共同之处,比如op rollup类似于plasma,zk rollup类似于validium。
layer2主流方案有:
- op rollup。layer2版本的plasma,op rollup采用fraud proof机制。
- zk rollup。layer2版本的validium,采用zkSNARK或zkSTARK算法。
一. optimistic rollup
optimistic rollup继承了plasma的fraud proof机制,保障数据合法性。其基本思路是在以太坊上乐观接受operator的提交结果,然后等待第三方提交challenge。
工作原理
引用以下图描述op rollup的工作原理(图片来源):
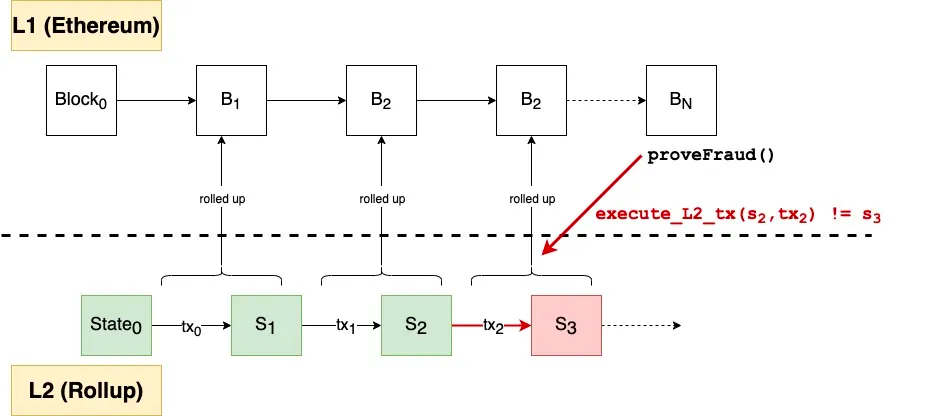
可以看到,整体思路和plasma大致相同:
- op rollup定期提交交易数据以及state root到以太坊。
- optimistic, 以太坊先乐观认同operator的提交,把交易数据和state root上链。
- fraud proof,存在上链的窗口期(challenge),一般为7天,等待第三方提出欺诈证明,并验证欺诈。
- 奖惩机制,根据challenge的结果进行奖惩。
op rollup和plasma对比如下:
| 分类 | DA | 支持智能合约 | fraud proof | tps,gas | proof validity |
| plasma | offchain | 不支持 | 是 | 优 | 难 |
| op rollup | onchain | 支持 | 是 | 一般 | 容易 |
此外op rollup还有一些值得注意的特性:
- pos机制。operator(validator)的产生往往采用pos机制,利于实现奖惩机制。当然也有完全中心化的operator。
- 数据压缩。operator需要把所有的交易数据打包,提交到以太坊,为节约存储空间,采用了数据压缩。这里有一个很好的例子,解析op rollup提交到以太坊上的数据。
- OVM。当发生欺诈时,需要在以太坊上重新执行对应的layer2交易。op rollup在以太坊的合约中内置了一个OVM(optmism叫做OVM,而Arbitrium叫做AVM),模拟layer2的环境,重新执行对应交易。这里详细介绍了OVM如何工作的。
- 挑战次数。当欺诈发生时,在挑战者和被挑战者之间可能会多轮交互,一般是两种策略:
- single-round。一轮交互,代表产品optimism。挑战者发出挑战,由OVM重新执行交易,判断最终结果。这种流程比较简单,但是成本高,OVM重新执行交易,需要挑战者提供额外的数据到layer1以太坊,即增加了layer1的上链数据,也需要消耗对应gas费。
- multi-round。多轮交互,代表产品Arbitrium。核心思路是把交易的执行分成很多step,然后寻找出最小的step执行,具体如下:
- challenger对某个交易发起挑战。
- asserter(被挑战者),把该交易二分法(bisection protoco)分成两半,等待challenger继续。
- challeger挑战其中有问题的那一半。
- asserter继续把step细分为两半,等待chanllger挑战有问题的那一半,如此反复,最终chanllenger确定有问题的最小step。
- 在layer1上面重新执行该最小step。挑战结束
需要注意的是,multi-round整个挑战过程是在l2上面完成的,l1会负责验证挑战的有效性,以及仅重新执行最小的挑战单元。考虑到l2无论是gas费,还是执行速度都远远优于l1以太坊,因此整个过程减少了l1的负担,从成本和执行效率的角度,多轮交互是优于一轮交互的。
- liquidity provider(LP)。引入解决liquidity provider撤回时间慢的问题。LP相当于中间商,用户可以把正在撤回中的资产转移给LP,LP确认资产无争议以后,直接放款给用户,收取一定的手续费,然后由LP来完成具体的挑战流程。
op rollup总结
- 用经济模型防止作恶。采用fraud proof机制,区块在l1上确定(finality)存在7天的挑战期(challenge)。
- withdraw慢,需要等待7天。
- LP可以有效解决withdraw慢的问题。
- 支持智能合约。
- 以太坊控制DA。
- op rollup流程简单,用户接受度高,目前TVL排名超过zk rollup。
二. zk rollup
zk rollup采用zkSNARK或zkSTARK数学算法保障数据的安全性,和optimistic rollup通过经济模型保障不同。zk rollup更为高效和安全,但技术门槛和硬件要求高,不利于operator参与。
工作原理
(1).zk算法
zk算法是整个zk rollup的核心,非常复杂,这里以zk-SNARK为例,简要的描述算法的核心思想。
1. verifier和prover
zk-SNARK算法中,如下图(图片来源),一共有两个角色:
- prover。提交proof证明给Verifier
- verifier。验证proof的有效性
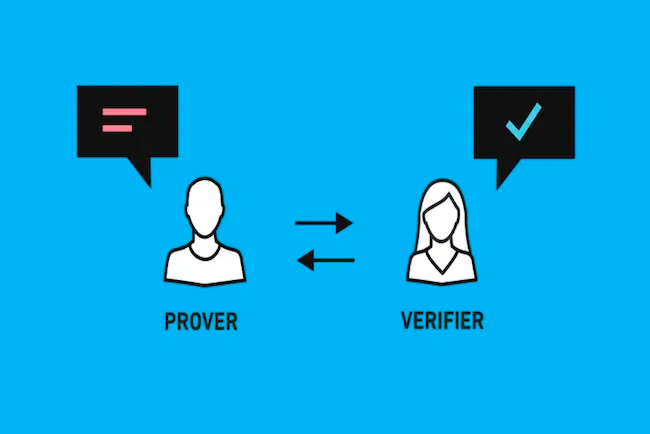
vitalik这里有篇精彩的文章,我们引用他的例子。整个zk证明流程为:
- 有一个公式f(x)=x**3 + x + 5。
- Prover想要证明两个结论:
- 结论1) prover申明输入x=3,则f(x)=35。
- 结论2) prover执行了完整的运算过程
- Prover提交proof给Verifier
- Verifier通过proof验证Prover诚实
2. constrain和多项式
这里记住prover要证明什么非常重要:
- 结论1) prover申明输入x=3,则f(x)=35。
- 结论2) prover执行了完整的运算过程
我们来看下怎么证明
- 结论1),prover申明输入x=3,则f(x)=35
这个结论似乎非常容易证明,verifier把prover提供的x=3直接代入公式,运算一遍就可以,这是因为这里使用了一个简单的公式,比如说是一个非常耗时的运算,运算一次需要10分钟,那么verifier重新运算一次的成本非常大。verifier在不重新执行运算的前提下,能够验证运算结果。是必要条件,在计算领域,这是一种NP问题,即仅验证结果,不求解。
对应真实的zk rollup场景中,prover负责交易的执行,而verifier是不会把交易重新执行一遍进行验证的。在这里,结论1得通过结论2来证明。
- 结论2),prover执行了完整的运算过程
这个结论的目的是为了推断结论1。想一下,在不重新执行运算的情况下,要证明一个结果正确,那怎么做?Prover这里的做法是把公式分成一个个的小步骤,一个小步骤叫做一个约束(constaint),如下有四个约束:
sym_1 = x * x y = sym_1 * x sym_2 = y + x out = sym_2 + 5
然后Prover把输入和小步骤中的生成值(x,sym_1, y, sym_2, out)当作proof都交给verifier。这些值都是公式的中间值,换而言之,只要(x,sym_1, y, sym_2)正确,out也一定正确,verifier就能得出结论:
- prover一定执行了完整的运算过程。否则不可能有正确的中间值
- x=3的时候,f(x)=35是正确的,因为中间值都是正确的
你一定会想,如果所有的中间值都验证一遍,那不就相当于verifier重新执行了一遍逻辑吗?对的,但这里你先假设有一种手段,不用计算也能验证中间值。那么上面的逻辑就没问题:输入和中间值正确,结果就正确。原因是他们满足约束(constraint)。
约束就相当于关系描述,比如约束sym_1 = x * x,就是描述sym_1和x之间满足的关系。
又比如说有人给叫你猜一个动物,给你几个约束:
- 会嘎嘎叫
- 一种家禽
- 会游泳
你根据这些约束很大概率会猜出是鸭子。也可能猜是鹅,因为约束并不多,鹅也会嘎嘎叫。
回归主题,contrain描述了输入和输出之间的关系。zk算法的核心本质为:prover提供(输入, 输出,中间值)三元组作为proof,verifier根据contraint验证输出的正确性。
下一个问题是如何验证中间值了,自然不可能是把每个中间值执行一遍,这就相当于verfier重新执行一遍公式了。于是数学家们引入了一个trick,简单的说,就是把多个约束,合并成一个最终约束,只需要执行这个这个约束就可以一步验证通过,大致流程为:
- R1CS。把多个约束整理成方程组形式,再把方程组变为向量运算
- QAP。利用多项值插值,把向量运算转化为一个多项式方程
这样上面的四个运算步骤,最终会变成一个多项式方程,你可以在这里试一下。达到了多个约束合并成一个约束的目的。
引入多项式方程作为最终约束有两个好处:
- 执行一次运算,就可以验证所有的中间值和结果
- 不同多项式方程之间差别很大,哪怕仅仅一个系数的改动,曲线形式都大不相同,可以减少冲突的可能性,也就是避免多项式A的解,恰好可以作为多项式B的解
以上就是SNARK算法的极简原理。但篇幅有限,还有大量的细节未描述,比如引入PCP随机抽查,即不一定执行所有的约束,随机验证几个约束看是否满足条件。比如zk的部分,通过同态加密隐藏真实数据,比如Elliptic Curve Pairing,把计算域从数阈转换成椭圆曲线等。
算法细节可以参考Why and How zk-SNARK Works: Definitive Explanation。
3. 电路
电路也是zk算法中比较困扰人的地方,为什么需要使用电路?
前面举例如何证明一个公式,而程序员面对的是代码,需要把代码转化成公式。事实上,所有算法都可以写成数学公式,了解函数式编程的对此有更深的体会。
比如有一段代码:
def qeval(x):
y = x**3
return x + y + 5
转换为数学公式就是f(x)=x**3 + x + 5
为了zk证明,进一步需要转换成能产生中间值的公式:
sym_1 = x * x y = sym_1 * x sym_2 = y + x out = sym_2 + 5
仔细观察转换后的结果其实就是一些简单的加法运算和乘法运算,完美的对应上了数字电路中的加法门,乘法门。
于是,那就干脆连最开始的代码都不用写了,直接用电路来写逻辑吧,于是就出现了这样的代码(这里是完整的circom示例):
//__1. verify sender account existence
component senderLeaf = HashedLeaf();
senderLeaf.pubkey[0] <== tx_sender_pubkey[0];
senderLeaf.balance <== account_balance;
component senderExistence = GetMerkleRoot(levels);
senderExistence.leaf <== senderLeaf.out;
for (var i=0; i<levels; i++) {
senderExistence.path_index[i] <== tx_sender_path_idx[i];
senderExistence.path_elements[i] <== tx_sender_path_element[i];
}
senderExistence.out === account_root;
//__2. verify signature
component msgHasher = MessageHash(5);
msgHasher.ins[0] <== tx_sender_pubkey[0];
msgHasher.ins[1] <== tx_sender_pubkey[1];
component sigVerifier = EdDSAMiMCSpongeVerifier();
sigVerifier.enabled <== 1;
sigVerifier.Ax <== tx_sender_pubkey[0];
sigVerifier.Ay <== tx_sender_pubkey[1];
//__3. Check the root of new tree is equivalent
component newAccLeaf = HashedLeaf();
newAccLeaf.pubkey[0] <== tx_sender_pubkey[0];
没错,这是一套常见的交易执行逻辑,只不过换成了电路实现。
因此,在zk rollup中,使用电路的目的,是要把逻辑拆分成一个个的中间步骤,专业术语叫做拍平(Flattening),用于产生约束和中间值。最终转化成多项式表达式参与zk计算。
4. zk算法小结
总结一下,zk算法的流程为:
- 把代码转换成电路(约束),目的是为了生成执行的中间值(trace)。
- 把约束转换成多项式,用于验证proof。
- prover运行电路代码生成生成proof,包括(输入,输出,中间值)
- verifier利用多项式验证proof
这样,verifier在不重新执行的情况下,也能验证输出的正确性,再结合加密算法,可以达到隐藏某些输入值或中间值情况下,也能验证输出的正确性。
结合circom工具,我们用上面描述来对应一个真实的zk rollup layer2开发流程,参考这里:
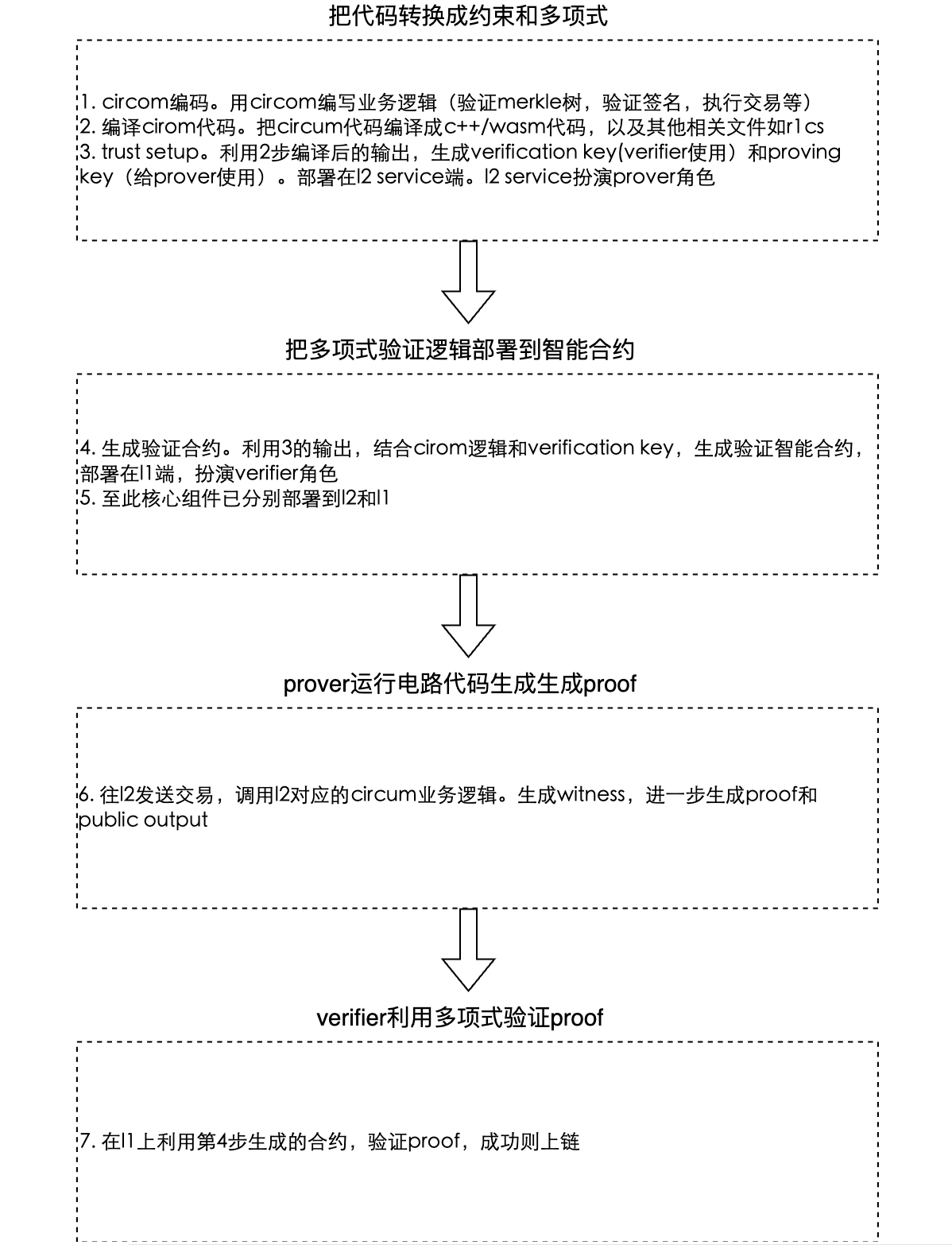
这里面要注意,l1上的智能合约中的约束,和l2中的电路是对应的,也就是如果l2中电路被修改,是无法在l1上通过验证的。
那么思考一下,在zk rollup中,operator能够偷走我的token吗?比如Alice给Bob转了10ETH,operator能够改成5ETH吗?
答案显然是不能的,因为Alice的交易会被做为zk算法的输入,如果篡改了,签名验证的验证电路就无法通过,即便operator篡改了电路,那电路逻辑就和lay1上部署的智能合约不一样,自然是验证不过的。
一个复杂的逻辑,尤其区块链交易逻辑,如果用电路实现,肉眼可见的复杂,而且要记录大量的中间值(又往往被叫做trace或者witness),显而易见的消耗资源。因此也不奇怪目前zk算法的两个通病:
- 硬件要求高。
- 通用计算困难,也就是支持简单的转帐交易容易,支持通用EVM困难,不过现在各种zkEVM已涌现,这一问题逐渐被解决。
(2). zkrollup流程
明白了zk算法,zk rollup的流程就很好理解,对比一下optimism(图片来源):
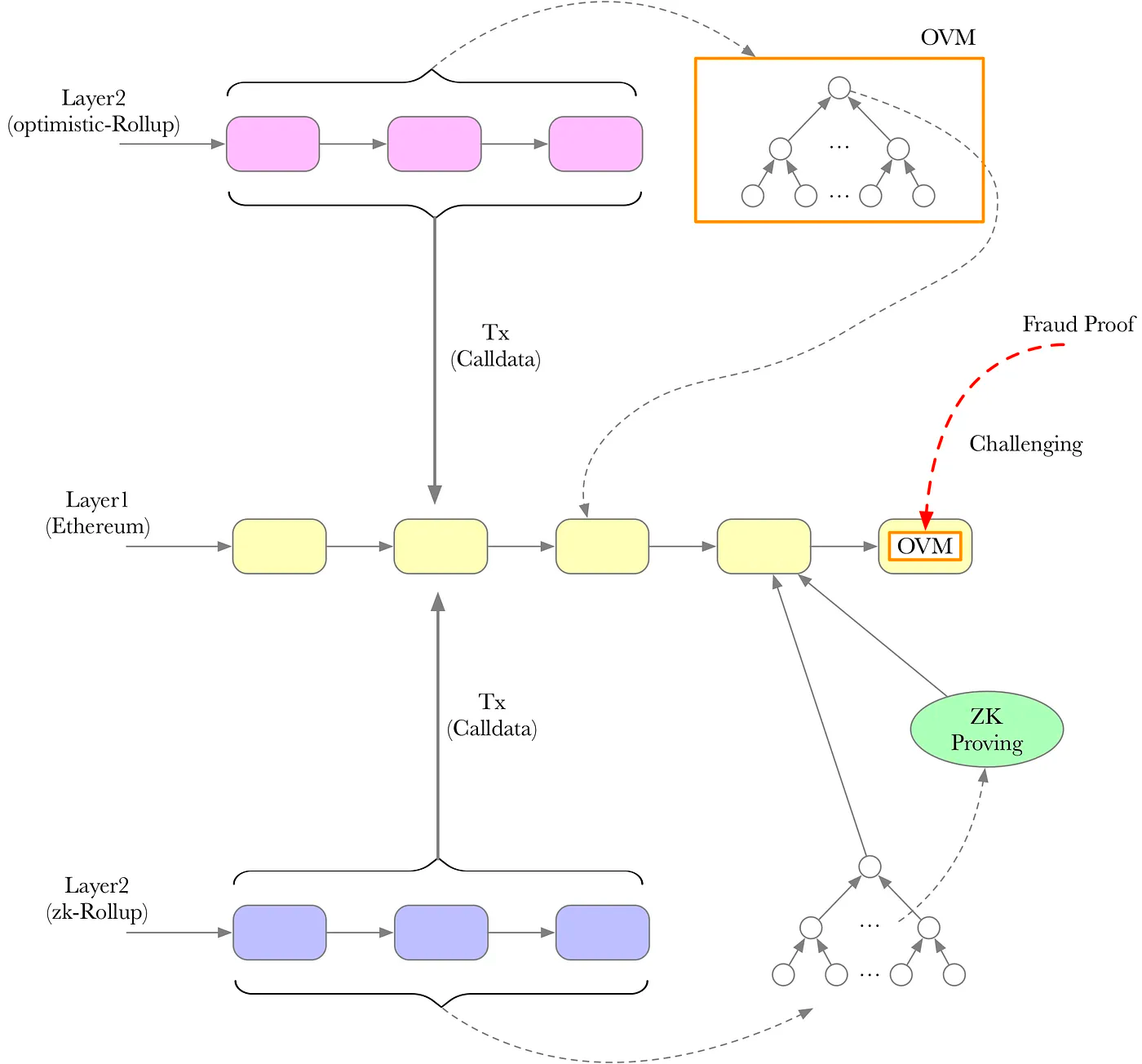
可见zk和op的流程,主要是在proof手段不同,op使用了OVM处理challege, zk用了zk proof。
zk rollup流程为:
- zk rollup定期提交交易数据以及state root到以太坊。
- Validity proof, layer2提交zk proof,以太坊layer1通过算法,确认交易的执行结果正确。
zk rollup总结
- 用算法确认交易合法性,无需信任。
- withdraw快,finality耗时在10m左右,主要是生成proof耗时。
- 一度支持智能合约困难,但现在问题逐渐解决。
- 技术和硬件门槛高。
zkr和opr对比
大致对比如下:
| 分类 | op rollup | zk rollup |
| DA | onchain | onchain |
| EVM兼容 | 兼容好 | 兼容困难 |
| proof | fraud proof | zk proof |
| finality | 7天 | 10分钟 |
| Rollup成本 | 低 | 高,计算proof消耗资源 |
| Liveness | user需要监控交易的运行状态 | user无需监控交易的运行状态 |
总的来说,zkr和opr难分优劣,zk rollup似乎架构上更优,但TVL上却是op rollup领先,主要的原因为:
- zk rollup理论上更安全,也更复杂,接受度不如op rollup。
- op rollup虽然存在撤回资产时间长的问题,但是LP的加入,对普通用户影响不大。
- op对EVM的支持良好,对DAPP友好,而zk则是支持困难,虽然最近有不少zkEVM出现,但未被普遍接受。
- op rollup采用了经济模型,zk rollup采用了算法模型,算法模型虽然更安全,市场表现并不一定优于经济模型,经济模型在生态圈更有优势。
- Gas费方面,如果区块打包交易量少,zk的gas更高,因为zk需要额外计算proof,而op不需要。如果交易量多,zk也不一定会占优势,取决于zk上链的数据。一般op rollup会把所有交易数据上链,看起来交易费会高于zk,但实际并非如此。这里有个比较。polygon zkEVM会把所有交易数据上链,而zkSync和Starknet则仅上链部分数据。上链全部数据则对比op没优势,上链部分数据虽然gas费低于op,但又会被诟病DA问题。
回复 laddery 取消回复