celestia作为一个DA链,自身定位于区块链世界中的网盘,本文浅析其工作原理和核心技术。
要解决的问题
作为DA链,要解决的问题用三个字就可以概括:”存,查,取“,celestia整个工作机制和技术,围绕这三个字展开。
存
存的问题很简单:celestia如何安全的存储数据?
为了保障数据的安全性,尤其是避免数据丢失,celestia采用了纠删码的方案存储数据,纠删码的核心就是:即使丢失一部分数据的情况下,依然能够还原出完整的数据。
这种特性无疑对数据的完整性提供极大的保障。
纠删码(Erasure Codes)技术是一种统称,celestia使用了具体的Reed-Solomon (RS) codes算法,在具体一点,使用了2d Reed-Solomon(RS)算法,具体算法细节此处不展开。
整体流程如下:
- 用户提交da数据到celestia, celestia打包到block中
- 把block数据划分成一个个固定大小的片段,叫做share,把share排列成k*k大小的二维数组(K值根据share数量计算,k*k约等于share数量)
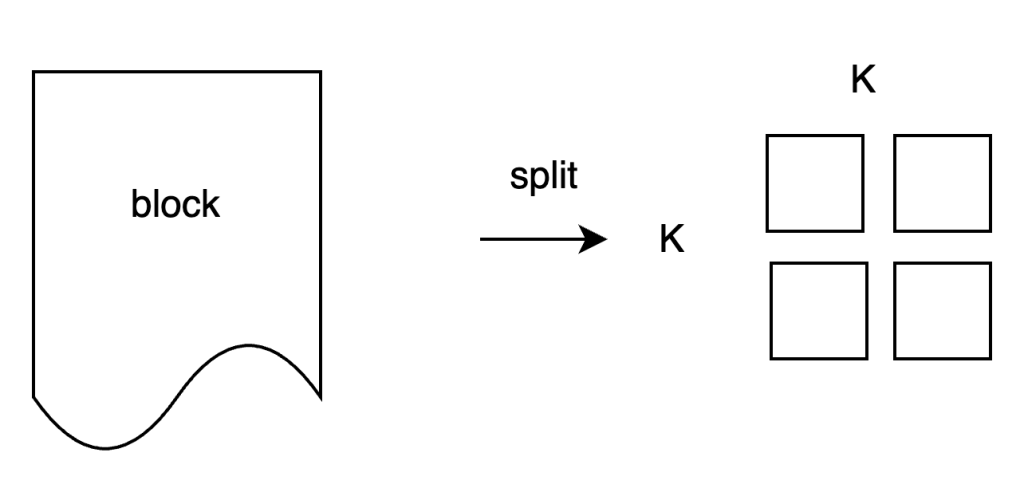
- 把K*K数组,使用二维纠删码算法(2d Reed-Solomon),扩展为2K*2K数组。
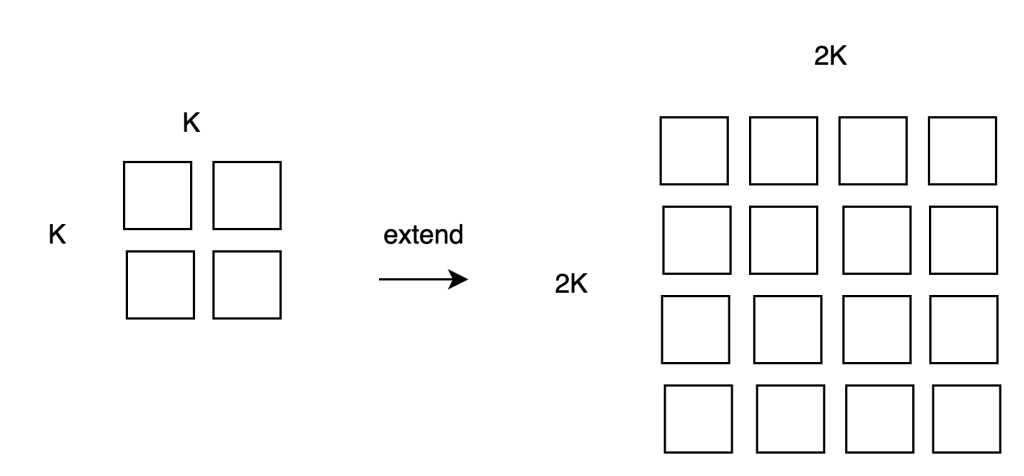
- 在celestia网络中广播该扩展后的数据。
使用了纠删码之后,节点同步扩展后的数据,好处是即使在50%的数据丢失的情况下,依然能够从剩余的50%数据中,还原成原始的block。
查
解决了存的问题,还有一个查的问题。
查的问题:怎么知道用户的数据已经存到了celestia的链上?
这个问题可以很简单:要想知道用户的数据是否存到了链上,把celestia链上的block都下载下来,挨个检查一遍不就可以了么?
当然也可以很复杂:如果不想下载celestia的block,如何确保数据已经上链了呢?
不下载celestia block的场景,其实是大多数用户面临的场景,毕竟用户可不想因为使用了celestia,就不得不同步完整的block,那样会消耗巨大的资源。
用户往往把自己定义为轻客户端(ligth client),要有一种方案,确保light client在仅同步block header,不下载block的情况下,确认block数据的有效性,这个问题叫做Data availability problem。详情可见https://coinmarketcap.com/academy/article/what-is-data-availability
celestia采用的解决方案是DAS,Data availability sampling。
- 首先,celestia采用merkle树的方案,把前面的2K*2K的share数据,生成data root。把data root保存在区块头block header里面。
- 其次,把block header广播给light client。
- light client从2K*2K的矩阵中随机选取一定数量的坐标,向celestia网络获取这些坐标的share数据,以及对应的proof,再把获得结果和header里面的data root对比,如果对比成功,说明网络大概率有了足够的share数据。这个过程叫做采样sampling。
- 重复步骤3一定次数,如果都能成功从celestia网络获取数据,那就可以确定block的数据,都已经在链上了
DAS的好处就在于,轻客户端通过采样,就能解决Data availability problem,在仅接收block header的情况下,不用下载block,就能确认block header中的数据真实上链。
取
取的问题也很简单:用户如何从链上获取自己的数据。
注意,这里是自己的数据,而不是其他用户的数据。celestia作为一条公链,有很多用户向链上提交数据,而每个用户,都只关心自己的数据,而不会关心其他用户的数据。
这要求用户数据要有唯一的标识。celestia使用了NMT, Namespaced Merkle Tree来解决该问题。
NMT本质是Merkle树,唯一不同的是在节点中带上了namespace数据,namespace可以理解为用户id,而且是可以有序排列的id。比如下图的NMT树中,红色和绿色数据,代表着分属不同的namespace。
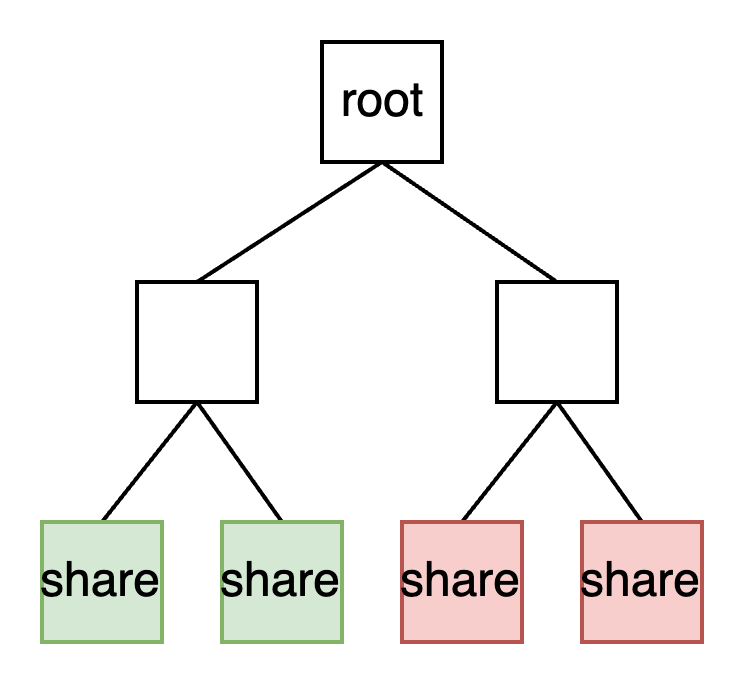
NMT有个好处,只要给定namespace,就能快速的定位到对应的分支(branch),进一步获取到用户真正需要的数据。
总结
本文极其概要的介绍了celestia的三个核心技术:Erasure Codes, das和nmt,以及其要解决的问题。
当然,要深入学习,还需要亿点点细节,本文限于篇幅不再展开。
回复 pqf64cd8e32f5ac7553c150bd05d6f2252bb73f68dpq 取消回复